
Históricamente el uso de las funciones definidas por el usario o UDF(User Defined Function) han representado una gran opción para el encapsulamiento de lógica dentro de objetos reusables de nuestras Bases de Datos, sin embargo, durante la implementación de una UDF escalar (una variante basada en la salida de la función) para MS SQL Server hemos estado sufriendo dolorosas penalidades de rendimiento hasta la llegada de la versión 2019, por lo que en este artículo, estaremos abordando como la nueva característica de Scalar UDF inlining nos ayuda a prevenir problemas de rendimiento y obtener el máximo valor en el código de nuestras Bases de Datos dentro de SQL Server.
Configurando nuestro entorno
La configuración, así como los componentes requeridos para este articulo paso a paso incluyen:
- MS SQL Server 2019: En mi caso, yo estoy ejecutando una instancia de SQL Server en Linux dentro de un contenedor Docker. Más detalles sobre cómo desarrollar su configuración puedes encontrarlo aquí.
- World Wide Importers DW: Esta Base de Datos es parte de los ejemplos disponibles para SQL Server, yo he seleccionado dicha BD en particular porque su tamaño es perfecto para el objetivo de este artículo, puedes descargarla aquí.
- Joe Sack code para mejorar la Base de Datos WWI DW: Este código es realmente muy valioso, yo descubrí este código gracias al excelente libro de Bob Ward (SQL Server 2019 Revealed) – gracias Joe.
- Azure Data Studio: Esta herramienta es opcional, puedes usar SSMS, en mi caso yo me encuentro en el proceso de aprendizaje de esta gran herramienta.
Exponiendo el problema de rendimiento de Scalar UDF
La conducta asociada al uso de Scalar UDF en versiones previas de MS SQL Server 2019 era terrible desde la perspectiva de su rendimiento como mencione en la introducción de este artículo, siendo la principal causa el hecho de que una Scalar UDF es invocado en forma de RBAR (Row By Agonizing Row). Probablemente, en mi opinión, el problema más peligroso es la forma en que Scalar UDF oculta los problemas de rendimiento, especialmente en el plan de ejecución, permítanme explicar esta situación a través de un ejemplo.
Bueno, es tiempo de jugar, por lo que la primera accion que haremos consiste en hacer nuestra Base de Datos WWI compatible con la ultima version compatible, para este caso es 150, ademas queremos habilitar la configuracion de la base de atos a nivel individual, por lo que ejecutaremos el siguiente código:
USE WideWorldImportersDW
GO
ALTER DATABASE WideWorldImportersDW
SET COMPATIBILITY_LEVEL = 150
GO
ALTER DATABASE SCOPED CONFIGURATION
GO
Llegados a este punto, estamos listos para iniciar con una explicación sobre el contexto y la generación de nuestras pruebas. Lo primero es como exponer el caso de uso RBAR, pero antes quiero simplemente delimitar el escenario, tenemos que crear una nueva tabla llamada Fact.OrderHistory usando el código de Joe Sack posteado anteriormente, específicamente con la ejecución del script: Update Intelligent QP Demos Enlarging WideWorldImportersDW.sql . Como puedes ver, este código usa la técnica GO N para multiplicar el número de filas en una tabla a partir de las mismas filas contenidas en ella, por lo que tenemos un tabla de gran tamaño lo cual es exactamente lo que estamos buscando.
Una vez que hemos construido nuestra tabla Fact.OrderHistory , es requerido encontrar todas las filas en esta tabla cuya columna [Order Date Key] corresponda al primer día del mes, para este próposito propongo que usemos una función simple: DATEFROMPARTS (mas detalles aquí), permitanme mostrales un ejemplo:
SELECT DATEFROMPARTS(YEAR(SYSDATETIME()),MONTH(SYSDATETIME()),1)
Nota: Les recomiendo el capitulo 7 del libro T-SQL Querying book de Itzik Ben-Gan donde encontraran autenticas joyas sobre como trabajar con fechas y tiempo, así como otros tópicos muy interesantes.
Espero que ejecutes el código anterior y confirmes el resultado, es simple y facil de aplicar, por lo que el siguiente paso consiste en la ejecucion de una consulta contra la tabla OrderHistory la cuál usara como entrada para el predicado una adaptación de la función DATEFROMPARTS, permiteme mostrarte el código:
SELECT [Customer Key],[Salesperson Key],[Description], [Tax Amount]
FROM Fact.OrderHistory
WHERE [Order Date Key] = DATEFROMPARTS(YEAR([Order Date Key]),MONTH([Order Date Key]),1);
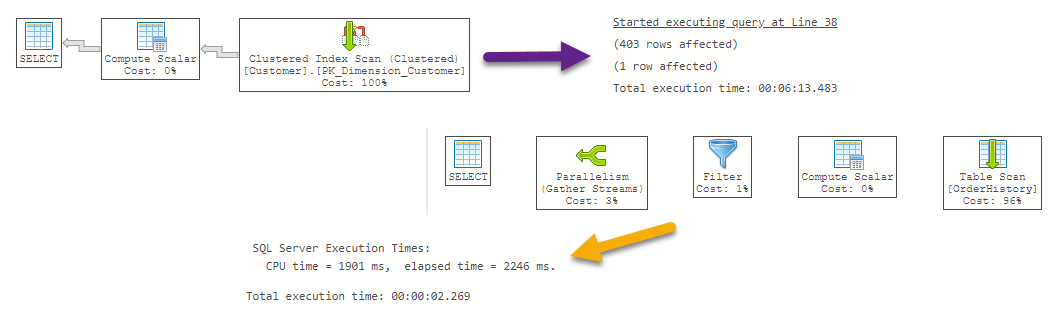
No haremos un analisis exhaustivo del Plan de Ejecución(PE), pero quiero remarcar las diferencias entre las consultas, en este caso, el PE es el siguiente con un promedio de 2 segundos en mi computadora (Core I7,16 GB, four cores)

Sin embargo, desde una perspectiva programática, el encapsulamiento de la lógica usada en la consulta es un gran candidato para ser parte de una función escalar definida por el usuario, el siguiente paso deberá consistir en crear una nueva función llamada FirstDayOfMonth la cual tendrá que recibir como único parámetro una fecha.
La siguiente sección de nuestro test consistirá en el remplazo del uso directo de la función DATEFROMPARTS por nuestra nueva funcion FirstDayOfMonth , como ya hemos configurado el Nivel de Compatibilidad a 150 (SQL Server 2019), obviamente, si estás trabajando en una versión inferior a 2019 puedes omitir la siguiente parte. Vamos a deshabilitar la característica integrada inline a través del usodeDISABLE_TSQL_SCALAR_UDF_INLINING.
-- Cleaning Cache
DBCC DROPCLEANBUFFERS
DBCC FREEPROCCACHE
SELECT [Customer Key], [Customer], [Dimension].[customer_category]([Customer Key]) AS [Discount Price]
FROM [Dimension].[Customer]
WHERE [Order Date Key] = (SELECT firstdayofmonth FROM dbo.FirstDayOfMonth([Order Date Key]))
ORDER BY [Customer Key]
OPTION (USE HINT('DISABLE_TSQL_SCALAR_UDF_INLINING'))
GO
Como podrás ver, el siguiente Plan de Ejecución solo nos muestra unos pocos pasos en comparación con la consulta previa que no estaba usando una función escalar definida por el usuario, por lo tanto podrías inicialmente pensar que es un buen plan debido a que está usando unos pocos pasos cuando en realidad está ocultando los problemas de rendimiento asociados, pero el tiempo de ejecución se han incrementado en una forma dramática como consecuencia de la función escalar definida por el usuario es invocada en RBAR, en tablas pequeñas o medianas probablemente el impacto del problema no es muy evidente, esta es la principal razón del porque usamos una tabla de gran tamaño donde puedes notar inmediatamente el síntoma del problema.


Resolviendo el problema de la función escalar definida por el usuario en versiones anteriores de SQL Server 2019
Probablemente en Internet puedes encontrar algunas formas interesantes de resolver el problema expuesto en la sección anterior de este artículo, sin embargo, he decidido compartir una forma ingeniosa y simple que encontré en el libro de Ben-Gan antes mencionado, este básicamente consiste en cambiar la definición de la función escalar para que use una Función de Valores de Tabla (mejor conocido como TVF) inline , aquí procedemos a cambiar el código:
DROP FUNCTION dbo.FirstDayOfMonth;
CREATE OR ALTER FUNCTION dbo.FirstDayOfMonth(@dt AS DATE) RETURNS TABLE
AS
RETURN
SELECT DATEFROMPARTS(YEAR(@dt),MONTH(@dt),1) AS firstdayofmonth;
GO
Las opciones que tienes para usar estos TFV es un operador explicito APPLY o a través de una subconsulta, para este caso estaremos usando una subconsulta como lo muestra la siguiente consulta:
SET STATISTICS TIME ON
SELECT [Customer Key],[Salesperson Key],[Description], [Tax Amount]
FROM Fact.OrderHistory
WHERE [Order Date Key] = (SELECT firstdayofmonth FROM dbo.FirstDayOfMonth([Order Date Key]))
OPTION (USE HINT('DISABLE_TSQL_SCALAR_UDF_INLINING'));
SET STATISTICS TIME OFF
Como podremos apreciar en las siguientes imágenes, la salida nos retorna los valores correctos que esperábamos en termino de tiempo y operadores involucrados en el Plan de Ejecución.
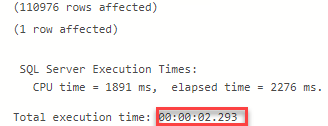

Función escalar definida por el usuario inline en SQL Server 2019
Y aquí estamos, SQL Server 2019 trajo consigo la función escalar definida por el usuario inline y otras muchas grandes características, por lo que estaremos seguros que el problema de rendimiento para las funciones escalares simplemente ha desaparecido. Permítanme regresar a la definición original de la Función escalar definida por el usuario.
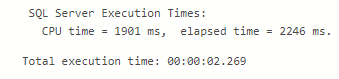
Regresando a la ejecución problemática de la consulta, usaremos nuestra Función escalar definida por el usuario y confirmar las estadísticas y el plan de ejecución.
Aquí las estadísticas y el Plan de Ejecución la cual tiene los números correctos y nos muestra como las cosas han retornado a la conducta esperada.

Conclusión
A través de este articulo hemos venido describiendo y reproduciendo los problemas de rendimiento asociados a las Funciones escalares definidas por el usuario en versiones anteriores a SQL Server 2019, hemos analizado la causa raiz de esta conducta asociada con la degradacion en el rendimiento con un alto impacto en nuestro Servidor debido al uso intensivo que genera una logica RBAR contra grandes tablas.
Afortunadamente, a partir de SQL Server 2019 este histórico problema ha desaparecido y podemos sentirnos seguros usando Funciones escalares definidas por el usuario, sin temor alguno sobre el impacto oculto en el rendimiento, además hemos visto una alternativa para gestionar el problema de rendimiento en versiones anteriores sin tener que reinventar la rueda. Espero que este articulo sea de utilidad, y recuerda que puedes escribirme para compartir tu opinión. Happy Querying!!!