
Recently, I was dealing with a task where I had to import raw information into a staging PostgreSQL Database as part of a task in the Airflow DAG pipeline. I would like to share the approach used and exposes the valuable Pandas.json_normalize function and how it helps to prepare the data before importing.
Reading the official Pandas documentation, we can find a simple and self-descriptive statement about this function which say: “Normalize semi-structured JSON data into a flat table”. The key parameter corresponds to the data which could be a dict or list of dictionaries, more info here.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
from pandas import json_normalize my_user = [{ 'firstname': 'Geo', 'lastname': 'Hernandez', 'country': 'Spain', 'username': 'gh', 'password': 'nothing', 'email': 'test@mycol.com'}, { 'firstname': 'Octi', 'lastname': 'Hernandez', 'country': 'Spain', 'username': 'oh', 'password': 'mypass', 'email': 'testoct@mycol.com'}] my_user_normalized = json_normalize(my_user) |
Once you execute it, you should see a result like this:
|
1 2 3 |
firstname lastname country username password email 0 Geo Hernandez Spain gh nothing test@mycol.com 1 Octi Hernandez Spain oh mypass testoct@mycol.com |
The output of json_normalize helps us to prepare the data for the next step. We are going to export/save the normalised output as a csv file. It is required to add an additional module (from Pandas) for using the function csv as part of a dataframe. As the output of json_normalize is a dataframe with the normalized format, it is not required to do any additional step more than execute the csv function.
|
1 2 |
my_path_csv = Path('YourPathHere/user_normalized.csv') my_user_normalized.to_csv(my_path_csv) |
At this point, we have a simple, but valid code for continuing working and now integrating Airflow. The flow that we are going to use in Airflow consists of the following steps:
create db table –> store_user_in_csv –> import_user_into_db
We are aiming to create a new table in PostgreSQL, for this objective, we could perfectly use the Postgres operator, additionally, is important to setup the connection info. You could add by code, in this case, we are going to use the simpler approach, you must go to Airflow UI and click on Admin –> Connections, once in there, it is required to submit the host, port, user and password. In our case, we will use the same PostgreSQL instance that is part of the Airflow configuration (and which stored the config data).
Here is an example:
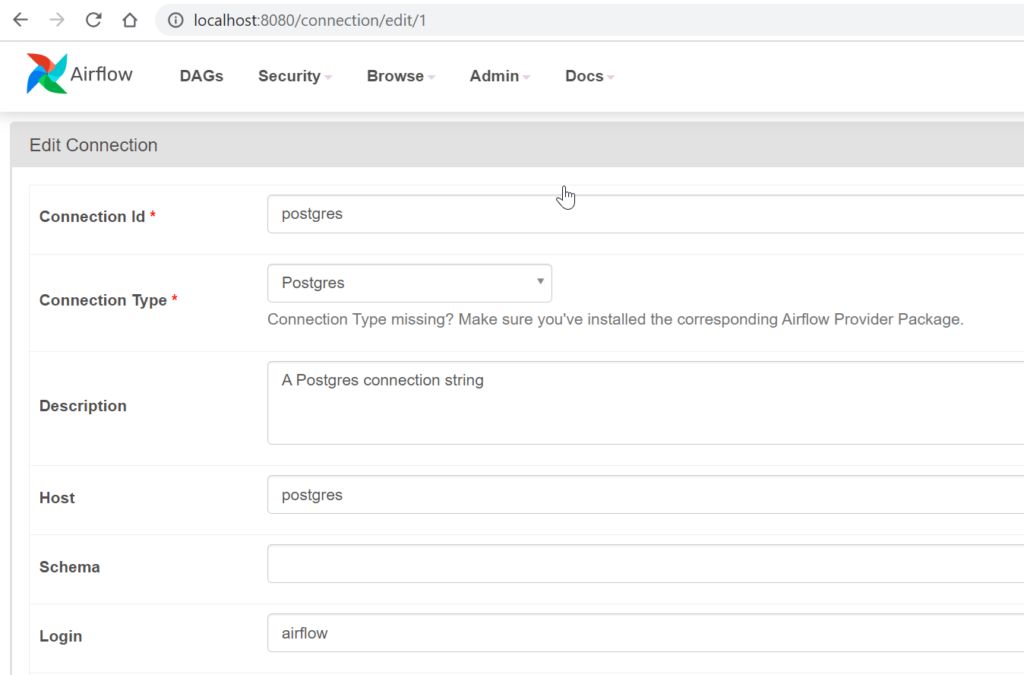
The first step requires that we use a special operator that helps us to interact against PostgreSQL database, as you can read here, there is a wide list of operators which represent an abstraction and we do not need to concern about how the operations are solved.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
from airflow.providers.postgres.operators.postgres import PostgresOperator create_db_table = PostgresOperator( task_id='create_db_table', postgres_conn_id = 'postgres', sql = ''' CREATE TABLE IF NOT EXISTS users ( firstname TEXT NOT NULL, lastname TEXT NOT NULL, country TEXT NOT NULL, username TEXT NOT NULL, password TEXT NOT NULL, email TEXT NOT NULL ); ''' ) |
As you can see, this operator requires three main parameters, the task_id is always recommended to have the same name as the variable, the postgres_conn_id which should correspond to the connection created in the previous step and finally the SQL code that we are going to execute, it should be idempotent.
The next key component is the import process, we have the possibility of using a special type of component called Hook, which can be defined as an abstraction of a specific API that allows us to interact with an external system, for instance: PostgreSQL, BigQuery, etc. The following example allows us to interact with Postgresq and execute a predefined task (copy_expert) which helps us to copy the content of the CSV file (stored as part of a Python task) into the table defined previously.
|
1 2 3 4 5 6 7 |
from airflow.providers.postgres.hooks.postgres import PostgresHook def _import_user_into_db(): hook = PostgresHook(postgres_conn_id='postgres') hook.copy_expert( sql="COPY users FROM stdin WITH DELIMITER as ','", filename="/tmp/user_normalized.csv") |
At this point, we are going ready to define the complete DAG code, here is the final version of the code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
from airflow import DAG from airflow.operators.python import PythonOperator from airflow.providers.postgres.operators.postgres import PostgresOperator from airflow.providers.postgres.hooks.postgres import PostgresHook from pandas import json_normalize from datetime import datetime from pathlib import Path def _store_user_in_csv(): my_path_csv = Path('/tmp/user_normalized.csv') my_user = [{ 'firstname': 'Geo', 'lastname': 'Hernandez', 'country': 'Spain', 'username': 'g', 'password': 'nothing', 'email': 'test@mycol.com'}, { 'firstname': 'Octi', 'lastname': 'Hernandez', 'country': 'Spain', 'username': 'o', 'password': 'mypass', 'email': 'testoct@mycol.com'}] my_user_normalized = json_normalize(my_user) my_user_normalized.to_csv(my_path_csv,index=None, header=False) def _import_user_into_db(): hook = PostgresHook(postgres_conn_id='postgres') hook.copy_expert( sql="COPY users FROM stdin WITH DELIMITER as ','", filename="/tmp/user_normalized.csv") with DAG( dag_id='storing_user_postgres', start_date = datetime(2023,6,2), schedule_interval = '@daily', catchup = False ) as dag: create_db_table = PostgresOperator( task_id='create_db_table', postgres_conn_id = 'postgres', sql = ''' CREATE TABLE IF NOT EXISTS users ( firstname TEXT NOT NULL, lastname TEXT NOT NULL, country TEXT NOT NULL, username TEXT NOT NULL, password TEXT NOT NULL, email TEXT NOT NULL ); ''' ) store_user_in_csv = PythonOperator( task_id='store_user_in_csv', python_callable = _store_user_in_csv ) import_user_into_db = PythonOperator( task_id='import_user_into_db', python_callable = _import_user_into_db ) create_db_table >> store_user_in_csv >> import_user_into_db |
Run the respective DAG and you should have a diagram and results like this:
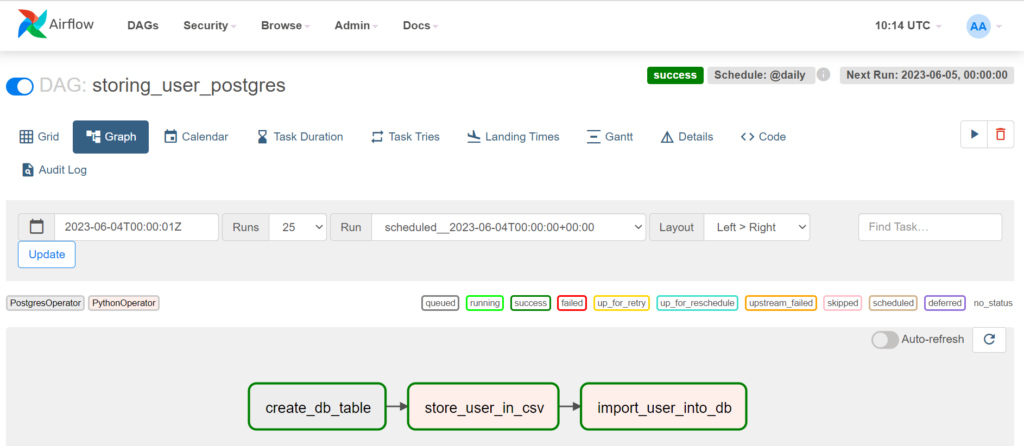
In case you need to confirm that everything was stored as expected, you could check the log of the import_user_into_db or connect to the PostgreSQL instance and query the table users. I hope this post would be useful and happy coding!