
The Apache Cassandra Database is one of the most growing and so scalable NoSQL technology available in the market with an increasing number of companies around the world using it. Every time that I start a new professional journey toward learning a new technology, It is so important to me count with the tools and a puppet project which give me the possibility to start practicing and including a realistic scenario where I would have the opportunity of consolidating any new knowledge acquired, hence having a Cassandra Cluster with many nodes is must, mainly because horizontal scaling is one of the main strengths of Cassandra.
The first step I decided to climb was setting up a laboratory for covering: installation, troubleshooting and best practices, however, at the time that I started to work in the build of this laboratory I could not find so many articles as I would like where is addressed how to set up a Cassandra Cluster on the Cloud and more specifically in Azure, this is the main reason for writing a series of articles dedicated to help you to setting up your first Cassandra Cluster on the Cloud, the main goal that I pursue in this series of articles is to show you in a detailed way the process of installing and configuring a new Cassandra Cluster from scratch, and additionally I will explain you how to create a Virtual Machine image that allows us to clone and give us the possibility of saving time and using for create new nodes based on the image already developed to accelerate the adding of new nodes to the existing Cassandra Cluster.
It is so important to highlight the laboratory we are going to configure is a right option for small Cassandra cluster and specially if you are interested in managing a basic load or simple use it for educational purpose.
This series of articles assume that you have basic knowledge in the follow technologies or tools: Ubuntu OS, vi editor, Azure, Azure CLI Tools.
In this article we will be covering the next sections:
- Laboratory Architecture
- Preparing our Azure Virtual Machine
- Installing Cassandra DB
Laboratory Architecture
The follow image shows you the laboratory solution proposed for a simple Cassandra Cluster composed by a group of three nodes and only one Data Center.
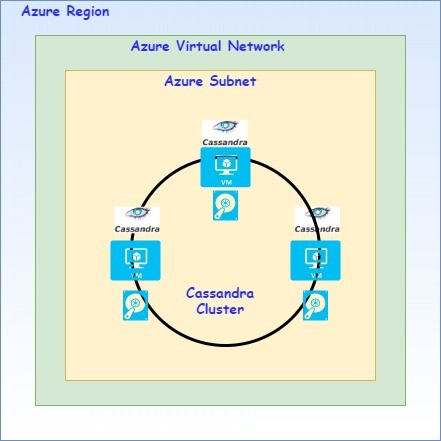
Even when we are targeting to Azure as our Cloud solution, the concepts and main components have their respective equivalence for other Cloud solutions as Amazon, Alibaba, or Google Cloud, so you should not concern about the Cloud platforms, obviously, this article is ideal for those that want to start directly into Azure, but you have the possibility of looking for the respective equivalencies in other Cloud provider and keeping the consistency clean enough.
Preparing our Azure Virtual Machine
In this section I am going to explain you the steps to follow for create our template or image VM, however, what exactly it means? It means we are going to create only once time a VM which must adapt to the configuration that we are looking for, no more and no less, the main objective of this image is to count with a valid and well configured VM which we will be able to clone and having new nodes ready to join to our new Cassandra Cluster during the configuration of our laboratory. I would like to mention that in general, the process of provisioning new nodes is managed through standard application like Ansible, Puppet, etc.
You should name the new VM as: cassandra-template, it is so important to use this name because in the final article of this series we would have many codes referenced it, the other important configuration consists in creating a resource group with the name: cassandra-group.
The OS installed in our VM is Ubuntu Server 18.04, the initial configuration of a new Azure VM is out of the scope of this article, but I encourage you to read the follow links which have a detailed explanation about creating a new VM and resource group.
https://docs.microsoft.com/es-es/azure/virtual-machines/linux/quick-create-portal
After that you have completed and deployed your new VM, you should create a dedicated user and group, it can be considered as a good practice especially because this user and group would be useful for the Cassandra Service into our server.
Here the commands for create the new group/user Cassandra
sudo groupadd -r Cassandra
sudo useradd -r -m cassandra -g cassandra -G users
First at all, we must install Java before try to install Cassandra, you could verify the Java version installed in your VM with the follow command
Java -version
In case that it is empty it means that we must install Java before to continue, the following procedure consists of a group of steps that give us a clean and full functional Java platform ready for our Cassandra installation. A very important first thing to be aware is the fact that since 16th April 2019 the Oracle JDK policy has changed, nowadays is mandatory for everyone interested in download JDK package to create an Oracle account and chose the required package version according to your OS, at the time that I am writing this article the last version is jdk-8u251-linux-x64.tar.gz, you can find more information in this link.
Once that you have downloaded the tar file, you shall copy it into your VM instance, my recommendation is creating a new folder and set up the required permissions for it:
sudo chmod a+rwx ./installer/
Unpacking the tarball into folder /usr/lib/jvm and check the content of target folder, for unpacking a .tar.gz file you could use the follow command:
sudo tar zxf jdk-8u251-linux-i586.tar.gz -C /usr/lib/jvm
At this point you have to let the OS know the new Java version, for doing this we must execute the alternatives command to do it, here more details about it.
sudo update-alternatives --install "/usr/bin/java" "java" "/usr/lib/jvm/jdk1.8.0_251/bin/java" 0
The expected output is the next:
update-alternatives: using /usr/lib/jvm/jdk1.8.0_251/bin/java to provide /usr/bin/java (java) in auto mode
Linux Notes
After complete the previous steps, we could run alternatives command to check this JDK release, in my case there is not another Java installation, for this reason the expected output corresponds only one alternative otherwise should be a list, here the command:
sudo update-alternatives --config java
The output in this specific case bring us only one alternative in link group java (providing /usr/bin/java): /usr/lib/jvm/jdk1.8.0_251/bin/java
If everything has been executed without errors, you should verify the current Java version recognized by OS and use again the java -version command as we did above.
This image shows us the expected output

However, sometimes you can find an error message like this:
bash: /usr/bin/java: No such file or directory
The main reason behind this error is the absence of 32-bit libraries, more details here, you shall install libc6-i386 library with the following command:
apt-get install libc6-i386
Installing Cassandra
At this point, we have our OS ready for advancing with the installation of Cassandra, there are plenty ways of installing it, I want to mention them:
- Building from Source (Apache Ant + GIT repo)
- Installing Debian packages (install a source binary tarball)
- Building Source Binary Tarball
In this article I will use the third option (Building Source Binary Tarball), this is my favorite way to go ahead with Cassandra installation, but you can feel free of choosing the option that make you feel more comfortable.
We have to start download the binary tarball, you can connect to this link, the last version at this moment is 3.11.6, you have two ways to do it, the first is download and copy to your VM as I did in JVM installation, or use curl command, in this case, I have chosen to use curl command, it is required to return our installer folder and from there execute the next commands:
curl -OL https://www.apache.org/dist/cassandra/3.11.6/apache-cassandra-3.11.6-bin.tar.gz

Now, we can unpack the installation files and later move it to the path /usr/share library. Here the sequence of commands to execute:
sudo tar -xzvf apache-cassandra-3.11.6-bin.tar.gz
sudo mv apache-cassandra-3.11.6 /usr/share/
That’s it, we have installed Cassandra without painful, I would like to recommend you think the possibility of creating a symbolic link to the directory, in the book “Expert Apache Cassandra Administration” the author Sam Alapti explained how/why we should consider creating a symbolic link , being the main benefit the fact of allowing us to have multiple versions of Cassandra in the same installation, the next command exemplified it:
sudo ln -s /usr/share/apache-cassandra-3.11.6 /usr/share/Cassandra
More references in this blog: https://linuxize.com/post/how-to-create-symbolic-links-in-linux-using-the-ln-command/
In this point, we have completed the installation of Cassandra, but I would like to add an extra configuration which can help us to work in our day to day, it basically consist in add a new path variable which has the path for Cassandra and we don’t need to reminder the complete path, I would like to highlight that we are using a source binary tarball installation, so the new path variable give us more flexibility as any functional shortcut, however other kind of installation has integrated this path variable per default.
For creating the path variable we need to edit the .bashrc file first, the bashrc is a script that is executed every time that we start a new terminal session, bashrc has a lot of setting and it is an integral feature of Ubuntu distribution, more details about this topic can be found in the follow link:
As part of the refinement process we are going to register the export inside the bashrc, you can use nano, atom, or your preferred editor, in my case vi, you should execute the following command:
vi ~/.bashrc
Inside the .bashrc file you must add the new entries using the export syntax, in my case I decided to create two variables and export them to PATH, these are CASSANDRA_HOME and CASSANDRA, the first one to have access to the main contents of our Cassandra’s main directories and the second one for being able to use every command which belongs to .bin folder, the follow statements are in charge of applying the changes mentioned above.
#Adding new home for Cassandra root path
export CASSANDRA_HOME="/usr/share/cassandra"
export CASSANDRA="/usr/share/cassandra/bin"
export PATH=${PATH}:${CASSANDRA_HOME}:${CASSANDRA}
Note: Sometimes would be required to restart your session before the changes being applied, therefore I recommend doing sudo reboot
For confirming that the path variables have been recognized you can simply execute an echo command like this:

One of the major benefits of using this path variables is the quick way for moving between directories, execute Cassandra commands directly without having to move to the bin directory.
As I highlighted at the beginning of this article, some specific steps are present here due to tarball installation selected, however from here in advance you can see a group of configuration steps which you should follow independently of your installation approach.
I used to recommend to set up three main directories aimed to store the data, they are commitlog, data, and saved_caches, however, even if you forget to create them it will be created automatically by Cassandra, but always is better to define these directories based on our preferences instead of letting to Cassandra decide by ourselves.
mkdir /usr/share/cassandra/commitlog
mkdir /usr/share/cassandra/data
mkdir /usr/share/cassandra/saved_caches
To complete this section, we are going to start Cassandra instance, for this purpose you have to use the command cassandra, it can be executed directly because we previously added the cassandra/bin to the path variable, so as this example show you:
cassandra -R
After to wait some minutes, finally the service would be ready and we could confirm his status using the nodetool status command, here the results:

Once we have reached this point of the article, we are starting to familiarize with the proposed architecture, we have built an initial template VM in Azure, installed Cassandra, and do some little amends for improving the functionality of our new model node. The following article which is part of this series will continue adding more features to finally have a fully functional Cassandra Cluster inside of an Azure platform.