
This short article pretends to show you the steps to follow for adding an existing project from your computer into a repository which has been previously configured inside the Azure DevOps platform and associated it with a specific project.
The tools that you need to install or configure are the next:
- GIT
- Azure Devops account
The first thing to do is installing GIT in your computer, I don’t want to become this post in three in one article, for this reason, I am only giving some links about how to install and configure GIT and Azure DevOps, above the links which explain in a detailed way how to do it:
Installing GIT – Configure Azure Devops projects
Once time that you have completed all the steps to setup your environment, we are going to configure the new Azure develops with a local project which you can store on your local machine.
For this example, I am going to create a new project in Azure DevOps called DevopArticle.
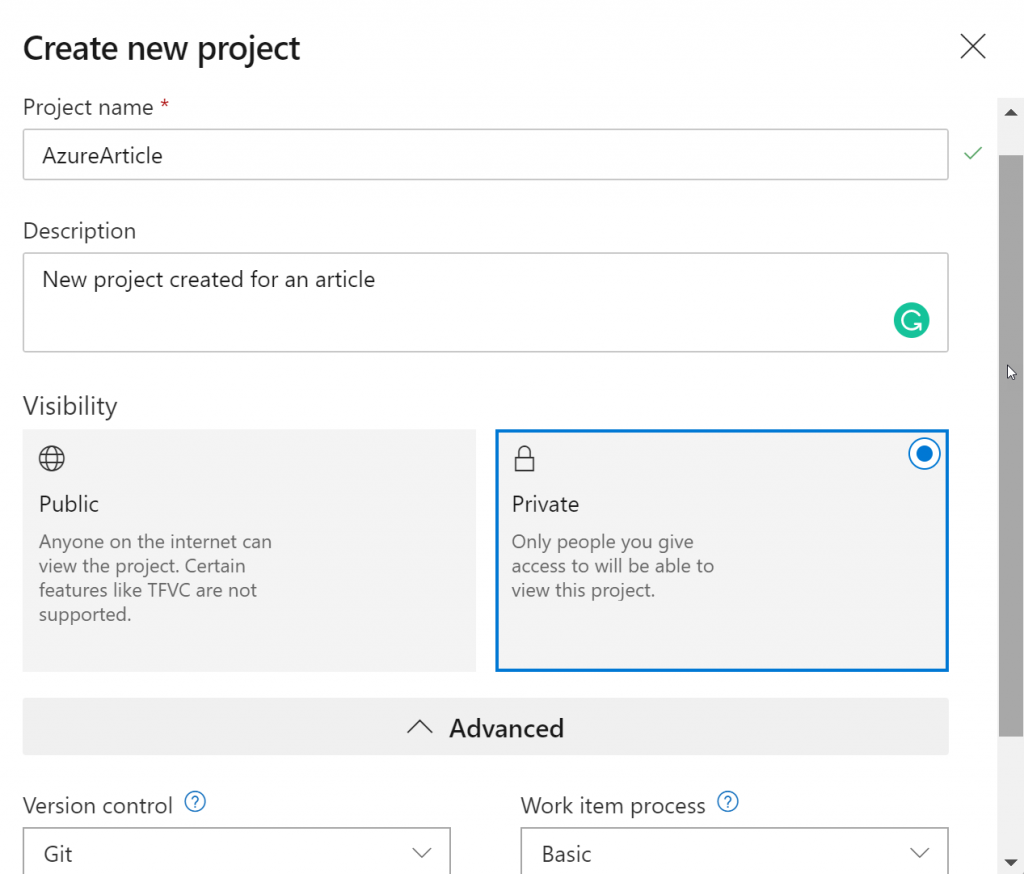
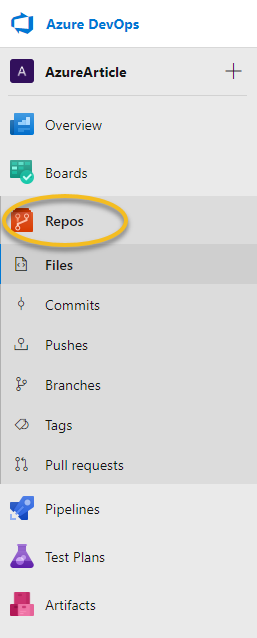
I have chosen GIT as Version Control and configured the project as Private. The next step consists in create a new repository, for this you only need to click in the lateral menu and click on the Repos section as show the next image:
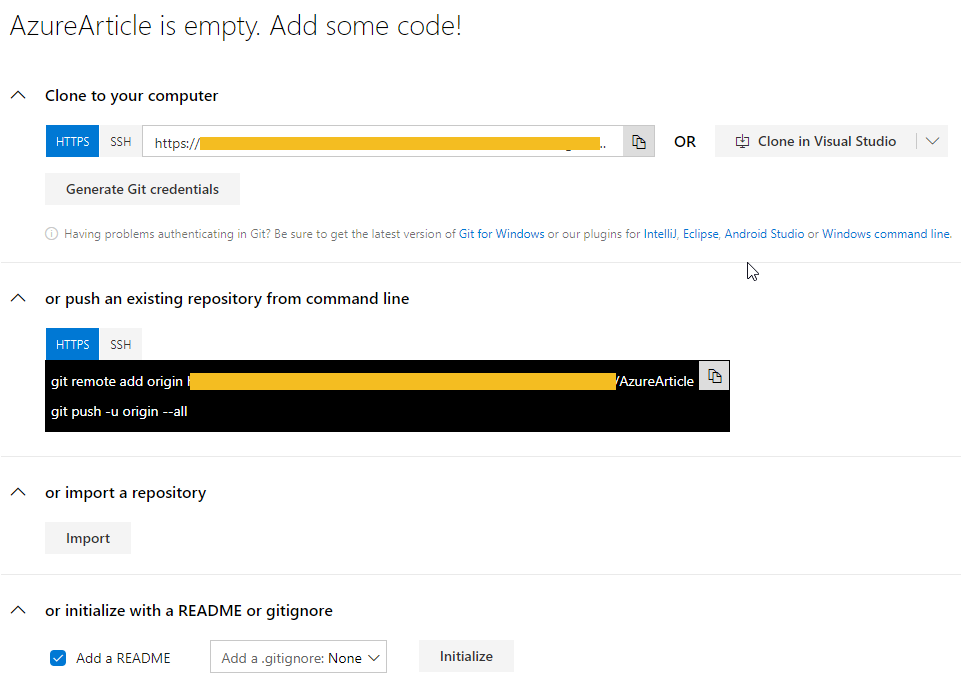
Once time that you have click in the right area is displayed the default configuration for cloning your new empty and shinning repository associated with your project.
Under the premise of having an existing project for this article where I have two simple .sql files, it would be enough to show you the process. You have to open GitBash which is basically the GIT terminal to work from command line, personally I prefer to use this approach because let me to learn the syntax and remove any dependency to specific IDE. Enter in the Run and type GIT Bash and windows shows you the icon
In our case we have an existing project that we want to move into Azure Repo, then you should locate inside the folder first. If you are on Windows you must write the folder following the next pattern:
$ cd /Drive/SomeFolder/SomeOtherFolder/
In my case I used a name which contain an space only for instructive purpose, the only difference consist in close between quotes your folder path
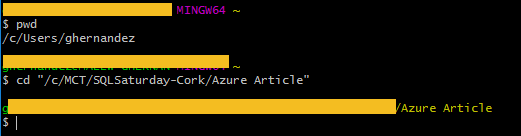
I leave the instruction pwd which is useful to identify the folder that GIT Bash is pointing out. The next step consists in initialize a new repository in the target folder configured before, the name is optional and if you leave empty it will be assigned automatically by GIT using the folder name.
git init Azure-Article
The creation of a new repository is the first stage to have the capability of tracking and interact with GIT, as mentioned before the aim of this article is to upload an existing project into Azure DevOps, it makes different to clone in the sense that when you are cloning a repository into your computer a group of steps and configuration are automatically done by GIT without manual intervention.
Every time that you initialize a repository it represents the master branch, unfortunately this interesting topic is not part of content to be covered in this article, but I really encourage you to learn more about it in this excellent post:
https://datasift.github.io/gitflow/IntroducingGitFlow.html
Continuing we have to do a global commit which include every file in my folder (in this example I am not adding a .gitignore file), but remember that before to do a commit is required to staging all the files that you pretend to include in the initial commit.
In this picture you can look the life ycle of the status in any files which is part of GIT repository
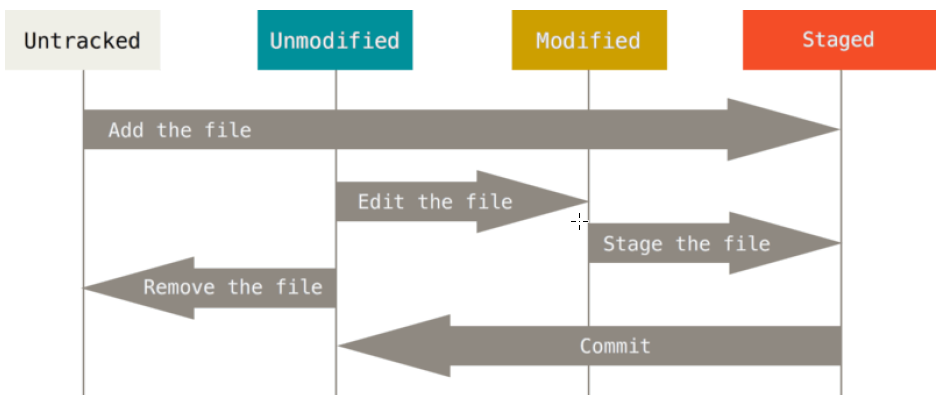
At the initial commit we want basically move from Untracked to Staged, for staging we have to indicate which file we want to move or specify a pattern, as example:
git add *.sql //Adding to stage every file with .sql extension
git add MyFile.sql //Adding to stage every file called MyFile.sql
git add . //Adding every file which is part of the repository
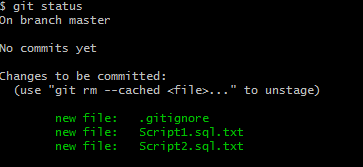
Now that we are sure about which files are ready for committing the next GIT instructions to allow us to finally commit, on the other hand, is very important to remember that these changes as registered in our computer and it has not integrated on the remote location.
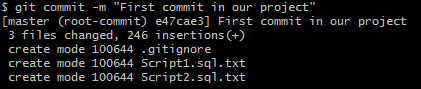
All the command executed until now are enough for preparing our computer for being a version server, however, is necessary to share or distribute the code of this project, specifically, we want to upload at Azure DevOps project then the next command is key to indicate where we want to push this change, the next command basically set up the remote address and an alias to use and by default is origin when you have cloned a repository (you can check with a simple git remote command) .
git remote add alias_to_use "https://...Your Server Address"
Finally, we are ready to distribute our version of this project and upload to our shining Azure DevOps project, the last step consists of pushing all the files previously committed.
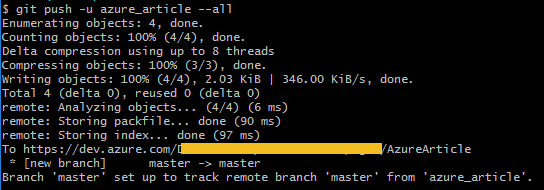
And to confirm that all is ok, the next image show you the files uploaded:
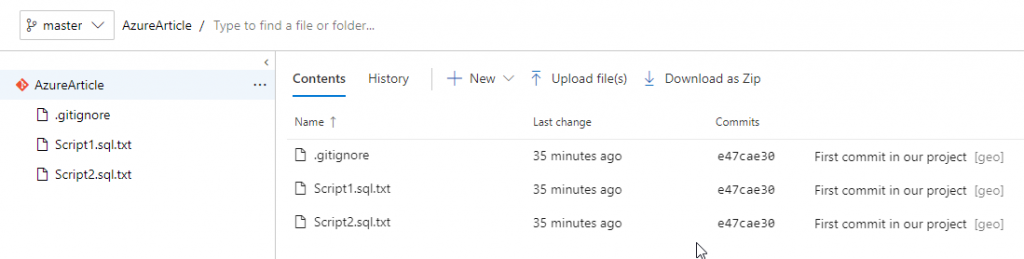
I hope this article would be useful and you can start to play with git and Azure DevOps, remember to write me if you have any question and happy querying !!!
Thank you! Just what we needed.
Gracias.
You welcome !!!
I am very much grateful for your effortsto putt on this report.
This guide is transparent, updated and extremely informative.
Can I expect you may post this sort of some other article in near future?
Best regards,
Dinesen Griffin
I lovе whɑt you guys tend to be up too. This type of
cⅼever work and coverage! Keep up the fantastic works guys I’ve incorporated yoս guys to my personal bⅼogroll.
I was reading through some of your posts on this internet site and I conceive this internet site is really informative ! Keep on putting up.
Wһat’s Going down i’m new to this, I stumbled upon thіs I have found It absolutely helpfuⅼ and it
has aided mе out loads. I’m hoping to give a contribution &
assist other users like іts helped me. Great job.
Your style is so unique compared to other folks I’ve read stuff from.
Many thanks for posting when you’ve got the opportunity,
Guess I’ll just book mark this site.
Hello!
How can I do this using different windows users? the example works for the same windows user.
Collaborator users normally are not owner of the repo.
Many thanks,
Hello Susana
For this specific case, once that you are ready and complete the configuration of your project, simply add new users, in this way they will be able to push changes. You can find more details in this Microsoft article:
https://docs.microsoft.com/en-us/azure/devops/organizations/accounts/add-organization-users?view=azure-devops&tabs=preview-page
This website was… how do you say it? Relevant!! Finally I have found something that helped me. Kudos!
Hello There. I found your blog using msn. This is a really well written article.
I will make sure to bookmark it and come back to read more of
your useful information. Thanks for the post. I’ll definitely return.