
Historically the use of User Defined Functions aka UDF has represented a great option to encapsulate logic into Database reusable objects, nonetheless, during the implementation of scalar UDF (a variation based on the function’s output) for MS SQL Server we have been suffering painful performance penalties until the arrival of version 2019, so in this article, we are going to address how the new Scalar UDF Inlining feature helps us to avoid performance problems and get the maximum value in our Database code inside SQL Server.
Contents
Setting up the environment
The setup and components required to follow this article step by step, includes:
- MS SQL Server 2019: In my case, I am running SQL DB in a Linux Docker Container. More details about how to configure it here.
- World Wide Importers DW: It is part of the SQL Server samples Databases, I chose it due to the size which is perfect for the objective of this article, you can download it here.
- Joe Sack code to enhance WWI DW: This code is really helpful and I realize about it thanks to Bob Ward’s amazing book (SQL Server 2019 Revealed) – thanks Joe.
- Azure Data Studio: I am in the process of learning about this great tool, so let me recommend you this option.
Exposing the Scalar UDF performance problem
The Scalar UDF behavior in previous versions of MS SQL Server 2019 was awful from the performance perspective as I have mentioned in the introduction of this article, the main root cause was the fact that a Scalar UDF is invoked in RBAR(Row By Agonizing Row) way. Probably, in my opinion, the most dangerous issue is the way Scalar UDF hides the performance issues, especially in the execution plan, so let me explain this situation through an example.
Well, It is playing time, so the first action to do consists in made our WWI Database compatible with the last compatibility version, for this case is 150, beside this we want to enable database configuration settings at the individual database level, so the following code must be executed:
USE WideWorldImportersDW
GO
ALTER DATABASE WideWorldImportersDW
SET COMPATIBILITY_LEVEL = 150
GO
ALTER DATABASE SCOPED CONFIGURATION
GO
At this point, we are ready to start with an explanation of the context and generating the conditions of our tests. The first thing is how to expose the RBAR behavior of scalar UDF, but before I want to simply delimiter the scenario, we must create a new table called Fact.OrderHistory using the Joe Sack code posted above, specifically with the execution of the script:
Update Intelligent QP Demos Enlarging WideWorldImportersDW.sql
As you can see, this code uses the GO N technique to multiply the number of rows in a table from the same rows that it has, so after his execution, we have a very big table which is exactly what we were looking for.
Once that we have built our table Fact.OrderHistory, is required to find all the rows in this table whose column [Order Date Key] corresponds to the first day of the month, for this purpose I propose the use of a simple function: DATEFROMPARTS (more detail here), let me show you an example:
SELECT DATEFROMPARTS(YEAR(SYSDATETIME()),MONTH(SYSDATETIME()),1)
Note: I recommend you the chapter 7 of T-SQL Querying book by Itzik Ben-Gan where you will find authentic jewels about working with date and time and other topics.
I expect that you execute the previous code and confirms the result, it is simple and easy to apply, so the next step consist in a simple execution of a query against OrderHistory table and using as input of the predicate an adaptation of the DATEFROMPARTS function, let me show you the code:
SELECT [Customer Key],[Salesperson Key],[Description], [Tax Amount]
FROM Fact.OrderHistory
WHERE [Order Date Key] = DATEFROMPARTS(YEAR([Order Date Key]),MONTH([Order Date Key]),1);
We will not be doing an exhaustive analysis of the Execution Plan (EP), but I want to remark the differences between queries, in this case, the EP is the following with an average of 2 seconds in my laptop (Core I7,16 GB, four cores)

However, from a programmatic perspective, the encapsulation of the logic used in the query is a great candidate to be part of a Scalar UDF, the following step would consist of creating a new function called FirstDayOfMonth which must receive as a unique parameter a date value.
CREATE OR ALTER FUNCTION dbo.FirstDayOfMonth(@dt AS DATE) RETURNS DATE
AS
BEGIN
RETURN DATEFROMPARTS(YEAR(@dt),MONTH(@dt),1)
END;
GO
The next section of our test will consist of replacing the use of the DATEFROMPARTS function with our new FirstDayOfMonth scalar function, as we have configured the Compatibility level to 150 (SQL Server 2019), obviously, if you are working in a lower version than 2019 you could skip the next part. I am going to disable the inlining integrated feature through the use of DISABLE_TSQL_SCALAR_UDF_INLINING.
-- Cleaning Cache
DBCC DROPCLEANBUFFERS
DBCC FREEPROCCACHE
SELECT [Customer Key], [Customer], [Dimension].[customer_category]([Customer Key]) AS [Discount Price]
FROM [Dimension].[Customer]
WHERE [Order Date Key] = dbo.FirstDayOfMonth([Order Date Key]);
ORDER BY [Customer Key]
OPTION (USE HINT('DISABLE_TSQL_SCALAR_UDF_INLINING'))
GO
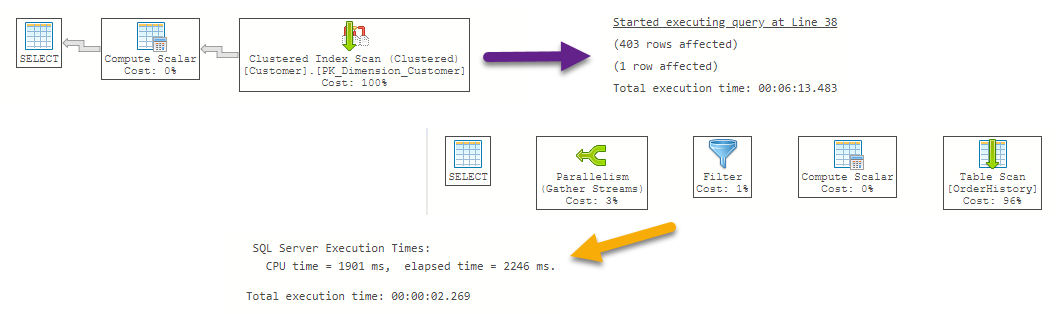
As you can see, the following Execution Plan only shows us a few steps in comparison with the previous query that was not using a Scalar UDF, hence you initially could think that it is a good plan due to is using fewer steps when in reality it is hidden the performance problems associated, but the execution time has increased in a dramatic way as a consequence of Scalar UDF is invoked in RBAR, in smaller and some medium tables probably the impact of the problem is not so evident, this is the main reason of using a huge table where you can notice immediately the symptom of the problem.


Workaround for Scalar UDF problem in previous SQL Server 2019 versions
Probably on the internet, you can find some interesting workaround for the issue exposed in the previous section of this article, nonetheless, I decided to share a very simple and ingenious solution found in Ben-Gan’s book mentioned before, it basically consists of changing the definition of Scalar function to use an inline Table Value Function(TVF), here the change in code:
DROP FUNCTION dbo.FirstDayOfMonth;
CREATE OR ALTER FUNCTION dbo.FirstDayOfMonth(@dt AS DATE) RETURNS TABLE
AS
RETURN
SELECT DATEFROMPARTS(YEAR(@dt),MONTH(@dt),1) AS firstdayofmonth;
GO
The options that you have to use these TVF is in an explicit APPLY operator or through a subquery, for this case we are going to use in a subquery as the following query show you:
SET STATISTICS TIME ON
SELECT [Customer Key],[Salesperson Key],[Description], [Tax Amount]
FROM Fact.OrderHistory
WHERE [Order Date Key] = (SELECT firstdayofmonth FROM dbo.FirstDayOfMonth([Order Date Key]))
OPTION (USE HINT('DISABLE_TSQL_SCALAR_UDF_INLINING'));
SET STATISTICS TIME OFF
As we can appreciate in the following images, the output returns the expected right values in terms of time and operators involved inside the Execution Plan
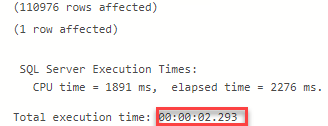

Scalar UDF inlining in SQL Server 2019
And we are here, SQL Server 2019 came along scalar UDF inlining and many other great features, so we are sure that the performance issue for scalar UDF simply has gone. Let me to return to the original Scalar UDF definition
DROP FUNCTION dbo.FirstDayOfMonth;
CREATE OR ALTER FUNCTION dbo.FirstDayOfMonth(@dt AS DATE) RETURNS DATE
AS
BEGIN
RETURN DATEFROMPARTS(YEAR(@dt),MONTH(@dt),1)
END;
GO
So returning to the problematic query execution, we are going to use our Scalar UDF and confirms the stats and execution plan
DBCC DROPCLEANBUFFERS
DBCC FREEPROCCACHE
SET STATISTICS TIME ON
SELECT [Customer Key],[Salesperson Key],[Description], [Tax Amount]
FROM Fact.OrderHistory
WHERE [Order Date Key] = dbo.FirstDayOfMonth([Order Date Key]);
SET STATISTICS TIME OFF
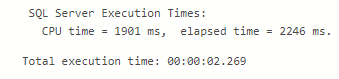
Here the stats and Execution Plan which have right numbers and show us how the things returned to the expected behaviour

Conclusion
Throughout this article we were describing and reproducing the performance issue associated with the Scalar UDF in previous versions than SQL Server 2019, analyzing the root cause and the behavior associated to degrade performance with high impact in our Server due to an intensive use which generates an RBAR logic against big tables.
Fortunately, since SQL Server 2019 this historic issue has gone and we can feel safe using Scalar UDF without concerns about the hidden impact on the performance, besides I have presented a simple approach to address this problem in the older versions of SQL Server without having to reinvent the wheel. I hope this article would be useful and remember to write me in case that you want to share your feedback. Happy Querying !!!